Ής’ΏΦρΫι
ΙπΝ÷
÷–Ιζ»Υ Ό…œΚΘ ΐΨί÷––ΡΘ§ΖΰΈώ¥ΠΨ≠άμ
¥χΝλΆ≈Ε”ΕάΝΔΉ‘÷ςΩΣΖΔΝΥ÷–Ιζ»Υ ΌΉ‘Ε·Μ·‘ΥΈ§ΤΫΧ®Θ§Μυ”ΎΩΣ‘¥ΤΫΧ®Ή‘ΩΣΖΔΘ§Ϋ®ΝΔΝΥΉ‘÷ςΦύΩΊΓΔΉ‘÷ςΝς≥ΧΓΔ“ΤΕ·‘ΥΈ§ΒΡ“ΜΧεΜ·÷«Ρή‘ΥΈ§ΧεœΒΓΘ
«Α―‘
±ΨΈΡ÷ς“ΣΫ≤ΒΡ «÷–Ιζ»Υ ΌΉ‘÷ς―–ΖΔΉ‘Ε·Μ·‘ΥΈ§ΤΫΧ®≥…ΙΠ“ΣΥΊΓΘ–¥ΝΥ÷–Ιζ»Υ ΌΉ‘Ε·Μ·‘ΥΈ§ΤΫΧ®¥”ΈόΒΫ”–’β―υΒΡΙΐ≥ΧΘ§≤Δ’β”–“Μ–©ΙΊΦϋΒΡ“ΣΒψΘ§Ηχ¥σΦ“Ήω“Μ–©Ϋι…ήΓΘ

…œΆΦ÷–ΒΡ’’Τ§ά¥Ή‘Άχ¬γΘ§Έ“‘χΨ≠ «ΗωΩλά÷ΒΡ¬κ≈©Θ§“‘«Α «Ήω“Μ–©±Θœ’“ΒΈώΤΫΧ®ΩΣΖΔΘ§±»»γ≥Β’Ψ¬κΆΖ≥ΥΩΆ“βΆβœ’≥ωΒΞœΒΆ≥Β»Θ§Κσά¥ΩΣ ΦΉω‘ΥΈ§Θ§’φ «“Μ»κ‘ΥΈ§…νΥΡΚΘΘ§ΟΜ”–ΉωΩΣΖΔΡ«Ο¥Ά¥ΩλΘ§“ρΈΣ”–ΚήΕύΩύ±ΤΒΡΨ≠άζΓΘ
1ΓΔ‘ΥΈ§÷°Χέ
ΧέΒψ“ΜΘΚœΒΆ≥Ζ±Εύ
“‘«ΑΈ“Ο«Ζ÷ΙΪΥΨΒΡΜζΖΩΩ…ΡήΟΜ”–Ρ«Ο¥ΙφΖΕΘ§Έ“Ο«ΉωΙβœΥ≤ΦœΏΒΡ ±ΚρΟΜ”–ΧχœΏΦήΘ§ΡΟ“ΜΗυPPΙήΑ―ΙβœΥ≤εΫχ»ΞΘ§Ϋ“ΩΣΜζΖΩΒΊΑε÷±Ϋ”¥”ΒΊΑεœ¬ΟφΑ―PPΥ°ΙήΆ±Ιΐ»ΞΘ§”Ο’β÷÷ΖΫ Ϋά¥¥νΙβœΥΝ§Ϋ”ΖΰΈώΤςΚΆ¥φ¥ΔΘ§Κή¥÷Ζ≈ΓΘ
Φ·÷–ΒΫ ΐΨί÷––Ρ‘ΥΈ§÷°ΚσΘ§÷ς“ΣΒΡ≤ζΤΖœΏ±»ΫœΕύΘ§ΧΊ±π «œώΈ“Ο«’β÷÷«ιΩωΘ§“ρΈΣΈ“Ο«œ÷‘ΎΦ·÷–÷ς“ΣΜΙ «ΈοάμΦ·÷–ΤδΟΜ”–¬ΏΦ≠Θ§ΨΆ «“ΜΗωœΒΆ≥ΨΆ «÷Μ”–36ΗωΖ÷ΙΪΥΨΘ§“Μ―υΒΡ ΐΨίΩβΩ…ΡήΨΆ «36ΗωΘ§Υυ“‘Έ“Ο«≤ζΤΖœΏ±»ΫœΕύΘ§’βΗωΨΆΒΦ÷¬Έ“Ο«”Π”ΟΒΡ ΒάΐΚΆ ΐΨίΩβΒΡ Βάΐ“≤±»ΫœΕύΘ§Έ“Ο«≈ζΉς“ΒΝΩ“≤ «±»Ϋœ¥σΓΘ
’βΗω«ΑΤΎΈ“Ο«‘ΎΟΜ”–…œœΏΉ‘Ε·Μ·ΤΫΧ®÷°«ΑΘ§Έ“Ο« «ΖΔΕ·ΝΥ»ΪΙζΖ÷ΙΪΥΨΒΡ–≈œΔ≤ΩΒΡ»ΥΝΠ“ΜΤπΗ…Θ§ΈΣ¥ΥΈ“Ο«ΜΙ“Σ≤Π≥ω“Μ≤ΩΖ÷Ζ―”ΟΘ§ΟΩ“ΜΡξΗχΥϊΟ«“ΜΒψΫ±άχΓΘ
ΧέΒψΕΰΘΚ…η±ΗΖ±‘”

Έ“Ο«ΒΡ…η±Η «±»ΫœΖ±‘”ΒΡΘ§¥σΦ“Ω¥’β’≈ΆΦΤ§Θ§ΚήΕύΖ÷ΙΪΥΨΒΡΜζΖΩΨΆ «’β―υΉ”ΒΡΘ§Β±»ΜΉή≤Ω ΐΨί÷––Ρ“ΣΙφΖΕΕύΝΥΓΘ
ΧέΒψ»ΐΘΚ±ξΉΦ‘”¬“
ΒΫΡΩ«ΑΈΣ÷Ι ΒΦ …œΈ“Ο«“―Ψ≠‘Ύ÷π≤ΫΒΡ»ΞΗΡ…Τ’βΗω«ιΩωΘ§ΒΪ «œ÷‘ΎΈ“Ο«ΜΙ «”–“Μ≤ΩΖ÷ΒΡ¥σ≤ΩΖ÷ΚΥ–Ρ ΐΨί «‘Ύ–ΓΜζ…œΟφ≈ήΓΘ±ξΉΦ±»Ϋœ‘”¬“Θ§Έ“Ο«Η’Η’ΉωΒΡ ±ΚρΘ§±ξΉΦ «±»ΫœΜ묓ΒΡΘ§≤ΌΉςœΒΆ≥“≤ «”–32ΈΜΒΡ”–64ΈΜΒΡΘ§redhat ”–5.4ΒΡΘ§”–5.8ΒΡΘ§Έ“Ο« ΐΨίΩβΑφ±Ψ”–“≤”–ΚήΕύ÷÷ΓΘ
ΧέΒψΥΡΘΚ≤ΌΉςΈό–ρ

’βΗω «“ΜΗωΉν¥σΒΡΈ ΧβΘ§ΨΆ «Έ“Ο«ΒΡ≤ΌΉςΘ§ ÷ΙΛ≤ΌΉς’βΗω «±»»γΥΒΈ“Ο«Ήω ΐΨίΩβΉΣΜΜΒΡ ±ΚρΘ§Μρ’Ώ «Κή¥σΒΡ“Μ–© ΐΨί«®“ΤΒΡ ±ΚρΘ§Έ“Ο«Ω…ΡήΜα¥σΝΩ≥ιΒς»ΪΙζΉωΝΌ ±ΒΡ≤Ι≥δΓΘ»Υ ÷≤ΜΙΜ «“ρΈΣΡψΟΜ”–œύ”ΠΒΡΉ‘Ε·Μ·ΤΫΧ®Θ§ΤΫ ±Έ“Ο«≤ΌΉςΒΡ ±Κρ“≤ «Α¥’’“ΜΗω≤ΌΉς ÷≤αά¥ΉωΒΡΘ§Εχ«“±δΗϋ“≤ΟΜ”–Ήω“ΜΗω”––ρΒΡΙήάμΓΘ
’βΗω“≤ «“ΜΗωΚή―œ÷ΊΒΡΈ ΧβΘ§Μυ±Ψ…œΫΎ «≥ωΝΥ ¬«ιΈ“Ο«ΩΣ ΦΉω±δΗϋΓΘΟΜ”–“ΜΗωΆξ…ΤΒΡΙφΜ°Θ§’βΗω“≤ «“ΜΗω±»Ϋœ―œ÷ΊΒΡΈ ΧβΓΘ“ΜΗω ¬ΦΰΒΦ÷¬“ΜΗω±δΗϋΘ§“ρΈΣ «ΟΜ”–ΦΤΜ°ΚΆΉι÷·Θ§ΟΜ”–Ψ≠Ιΐ―œΗώΒΡ“ΜΗωΦΤΜ°Α≤≈≈Θ§Υυ“‘ΥΒΆυΆυ”–Ω…ΡήΒΦ÷¬–¬ΒΡ ¬ΦΰΘ§±ΜΕ·ΒΊ±δ≥…“ΜœΒΝ–ΒΡ±δΗϋΓΘ
Ρ«Ο¥‘θΟ¥ΑλΘΩ’βΗωΜαΒΦ÷¬Θ§Έ“Ο«–η“Σ”–“ΜΗωΆ…±δΓΘ¥”¥ΪΆ≥ΒΡΤσ“Βά¥Ϋ≤Θ§Έ“Ο«Τδ ΒΆ…±δΒΡ’βΗω≥ΧΕ»ΜΙ «±»ΫœΆ¥ΩύΒΡΓΘ
2ΓΔΜ·Φκ≥…Βϊ
Ά…±δ“ΜΘΚ±ξΉΦΜ·
Έ“Ο«ΒΡΒΎ“ΜΗωΡΩ±ξΨΆ «ΫΪ¥σΝΩΒΡΩΣ ΦΉωX86ΚΆU2LΉΣΜΜΘ§Α―Έ“Ο«±Ψά¥ «‘Ύ–ΓΜζ…œ≈ήΒΡ”Π”Ο≥Χ–ρΉΣ“ΤΒΫX86ΤΫΧ®…œ»ΞΘ§Ϋχ“Μ≤ΫΉΣ“ΤΒΫ–ιΡβΜζΒΡ LinuxΓΘ
’βΗω”Π”ΟΗΡ‘λ «ΒΎ“Μ≤ΫΘ§Έ“Ο«Ά®Ιΐ’βΗωΗΡ‘λΈ“Ο«ΫΎ‘ΦΝΥ¥σΝΩΒΡ–ΓΜζΓΘœ÷‘ΎΈ“Ο«≥ΐΝΥΚΥ–ΡΒΡ ΐΨίΩβ‘Ύ’β–ΓΜζ…œΟφΘ§Έ“Ο«Μυ±Ψ…œΥυ”–ΒΡ”Π”ΟΖΰΈώΤςΕΦ «Μυ”Ύ Virtual LinuxΘ§Β±»Μ–ιΡβΜζ“≤”–“Μ≤ΩΖ÷ « win ΒΡΓΘΕχ«“œ÷‘Ύ≥ΐΝΥ vmware ÷°ΆβΈ“Ο«ΜΙ”–Ϋ®ΝΔΝΥΈ“Ο«“ΜΗω OpenStack Φ·»ΚΓΘ

Έ“Ο«Ήω OpenStack ΗχΈ“Ο«ΒΡ―–ΖΔΆ≈Ε” Ι”ΟΘ§Ά§ ±Έ“Ο«ΜΙ‘ΎΉωΈ“Ο«ΒΡ“ΜΗωΜυ”Ύ Docker ΒΡ“ΜΗω PaaS ΤΫΧ®ΒΡ―–ΖΔΓΘΈ“Ο«Ά®Ιΐ’β–©ΖΫ ΫΈΣΚσΤΎΒΡ±ξΉΦΜ·¥ρœ¬Μυ¥ΓΓΘ
Μυ¥ΓΤΫΧ®±ξΉΦΜ·

Έ“Ο«ΩΣ ΦΉω“ΜΗω±ξΉΦΜ·Θ§ Ήœ» «Ά≥“Μ“ΜΗω…η±ΗΒΡ≤…ΙΚ±ξΉΦΘ§Έ“Ο«Ά≥“ΜΝΥ“ΜΗω≤ΌΉςœΒΆ≥ΓΔ ΐΨίΩβΓΔ÷–ΦδΦΰΑφ±Ψ“‘ΦΑΈ“Ο«ΚήΕύΒΡΩΣ‘¥ΒΡΤΫΧ®Έ“Ο«“≤ «Ήω±ξΉΦΒΡΆ≥“ΜΜ·Θ§ΨΆ «”–Ά≥“ΜΒΡΙφΖΕΘ§“‘±ψΈ“Ο«‘ΥΈ§”–“ΜΗωΆ≥“ΜΒΡΙήάμΓΘ
”Π”ΟΦήΙΙ±ξΉΦΜ·
’βΗω «Έ“Ο«ΗυΨί“‘ΆυΒΡΫΧ―ΒΕ‘―–ΖΔ…œœΏΒΡ”Π”ΟœΒΆ≥Έ“Ο«Ήω≥ωΝΥ“Μ–©ΦήΙΙ…œΒΡΙφ±ήΘ§±»»γΥΒΈ“Ο«Ε‘Ζ«Φ·»ΚΒΡœΒΆ≥Έ“Ο«≤Μ‘ –μ…œœΏΘ§Μρ’ΏΥΒΡψ’βΗω «ΒΞΒψΒΡΘ§ΡψΟΜ”–≤…”ΟΦ·»ΚΦήΙΙΈ“Ο« «≤Μ‘ –μ…œœΏΒΡΓΘ
Ρψ”Ο ≤Ο¥ ÷ΕΈ±Θ÷ΛΡψΒΡ ΐΨίΩβ Βœ÷“ΜΗω»»«–ΜΜΘ§Ω…“‘”–“ΜΗωΗϋΩλΒΡΜ÷Η¥Θ§ΙφΕ®Έ“Ο«“ΜΗω≥ι»ΓΒΡ±ξΉΦΘ§Ρψ ΐΨί‘θΟ¥≥ι»Γ“≤“Σ”–“ΜΗωΙφΖΕΓΘ
Έ“Ο«ΚΆ―–ΖΔΨΆ¥ο≥…ΝΥ“ΜΗωΨΐΉ”–≠Ε®œύ”ΠΕ‘”ΎΡψΆΤΙΐά¥ΒΡΑφ±Ψ≤ΜΖϊΚœΙφΖΕΈ“Ο« «≤Μ‘ –μ…œœΏΒΡΓΘΈ“Ο«”Π”ΟΦήΙΙ±ξΉΦΜ·’β“ΜΩι «ΨΆ «ΆΤΕ·ΒΫ―–ΖΔΒ±÷–»ΞΖΔΜ”≥ωΈ“Ο«ΒΡ”ΑœλΝΠΓΘ
‘ΥΈ§Νς≥ΧΒΡ±ξΉΦΜ·

’β“ΜΩιΈ“Ο«–¬¥”–¬ΩΣ ΦΉω≥ω αάμΘ§œ» «¥””–…η±Ηά¥ΒΡ ±Κρ≈δ÷ΟΉ ‘¥…œœΏΚΆœ¬œΏΒΡΝς≥ΧΘ§ΒΫΑ―Έ“Ο«’βΗω…η±ΗΒΡΙήάμΙφΖΕΤπά¥Θ§»ΜΚσΈ“Ο«‘Ό…ηΝΔΈ“Ο«ΦΤΜ°±δΗϋΒΡΝς≥ΧΓΘ
œ÷‘ΎΈ“Ο«Μυ±Ψ…œΙφΕ®‘Ύ÷ή»ΐ”–“ΜΗω–Γ±δΗϋΘ§÷ήΈε“ΜΗω¥σ±δΗϋΘ§ΤδΥϊ ±Φδ «≤Μ‘ –μΉω±δΗϋΒΡΓΘ’β―υΈ“Ο«»γΙϊΥΒ”–±δΗϋΒΡΜΑΘ§Έ“Ο«ΕΦ“ΣΧα«Α“Μ÷ήΉω“ΜΗω±δΗϋΦΤΜ°Θ§Ά®ΙΐΤά…σ≤≈Ω…“‘‘Ύœ¬÷ήΉω“ΜΗω¥σ±δΗϋΓΘ
Έ“Ο«Ε‘”Ύ“Μ–©”Αœλ±»Ϋœ–ΓΒΡΘ§ΖΕΈß±»Ϋœ–ΓΒΡ–ΓœΒΆ≥Θ§Μρ’Ώ «ΧΊ±πΫτΦ±ΒΡœΒΆ≥Θ§Έ“Ο«Ω…“‘ΉωΫτΦ±ΒΡ±δΗϋΘ§Έ“Ο«ΫτΦ±±δΗϋΈ“Ο«“≤”–“ΜΗω…σ≈ζΝς≥ΧΘ§’β―υΨΆΑ―Έ“Ο«’ϊΗωΒΡ±δΗϋΒΡΙήάμ»ΟΥϊ”––ρΘ§»ΟΥϊ–Έ≥…“ΜΗωΑ≤»ΪΩ…ΩΊΒΡ“ΜΗωΉ¥Χ§ΓΘ
Έ“Ο«Ά§ ±“≤Ϋ®ΝΔΑ≤»Ϊ ¬ΦΰΒΡΙήάμΝς≥ΧΘ§“‘ΦΑΈ“Ο«±δΗϋΒΡ ÷ΕΈΘ§ΕΦΑ―ΥϋΉωΒΫ”–ΨίΩ…“άΘ§”–ΨίΩ…≤ιΘ§”–Ζ®Ω…“άΓΘ
≤ΌΉςΝς≥ΧΙφΖΕΜ·
≤ΌΉςΙφΖΕΒΡ±ξΉΦΜ·Θ§’βΗω“≤ «Έ“Ο«Ήω±ξΉΦ αάμΒΡ“ΜΗω÷Ί“ΣΒΡΕ·ΉςΘ§Έ“Ο«Α―Έ“Ο«ΒΡ÷Σ ΕΫ®ΝΔΝΥ“ΜΗωΈΡΒΒΩβΘ§Έ“Ο«Α―≤ΌΉς ÷≤αΦ·÷–Τπά¥Θ§ Ήœ»“ΣΉωΒΡ «ΈΡΒΒΙήάμΘ§Υυ“‘ΈΡΒΒΑφ±Ψ“ΣΆ≥“ΜΓΘ
Ά≥“Μ“‘ΚσΈ“Ο«ΒΡ±δΗϋΒΡ ±ΦδΫ®ΝΔ‘Ύ÷ή»ΐΒΫ÷ήΈεΒΡΑΥΒψ÷”“‘ΚσΘ§ΉωΒΫΕ®ΤΎΈ§ΜΛΓΘ
Ά…±δΕΰΘΚΙΛΨΏΜ·
œ¬“Μ≤ΫΨΆ «“ΣΫ®ΝΔΈ“Ο«ΒΡΙΛΨΏΘ§Έ“Ο«Α―±ξΉΦΜ·ΉωΚΟΝΥ“‘ΚσΨΆ“ΣΫ®ΝΔΈ“Ο«Ή‘ΦΚΒΡΙΛΨΏΧεœΒΘ§Έ“Ο«ΒΡΙήάμΙΛΨΏΘ§’βΗωΈ“Ο«œ÷‘ΎΜΙ‘Ύ”Ο
Νς≥ΧΙήάμΙΛΨΏ
Ά≥“ΜΒΡΝς≥ΧΙήάμΘ§Ά®Ιΐ“Μ–©Νς≥ΧΙέΒψΒΡΆ®÷ΣΘ§ά¥ΉωΒΫΈ“Ο«ΒΡ“ΜΗωΥυ”–ΒΡΝς≥ΧΒΡΆ≥“ΜΙήάμΘ§ΨΆ «œύ”ΠΝς≥ΧΑϋά®Έ“Ο«’βΗω»®œό…ξ«κΒΡΝς≥ΧΘ§Ά®Ιΐ’βΗωΤΫΧ®ΉΏΓΘ

Έ“Ο«”ΟΒΡΦύΩΊΙΛΨΏ“≤ «Μυ”Ύ“ΜΩν…Χ“Β»μΦΰΘ§ΡήΙΜΫβΨω¥σΕύ ΐΒΡΜυ¥ΓΤΫΧ®Ή¥Χ§ΦύΩΊΈ ΧβΘ§Εχ”Π”ΟΦύΩΊ’β“ΜΩι «±»Ϋœ±Γ»θΒΡ“≤ΕΦ”–“ΜΗωΙ≤Ά§ΒΡΆ®Βγ‘ΎάοΟφΘ§“ρΈΣΡψ «“άάΒ≥ß…ΧΘ§–¬ΒΡ–η«σΨΆ“ΜΕ®“ΣΕ®÷ΤΜ·ΩΣΖΔΓΘ
Ά…±δ»ΐΘΚΉ‘÷ςΜ·
»ΜΚσ≤ΌΉςΉ‘Ε·Μ·ΙΛΨΏ «»± ßΘ§’βΗω”ΠΗΟ «‘Ύ12ΡξΓΔ13ΡξΒΡ ±ΚρΘ§Έ“ ήΒΫΝλΒΦΒΡΈ·Ά–Ήω“Μ–©…Χ“ΒΒΡΉ‘Ε·Μ·≤ΌΉς»μΦΰΒΡ“Μ–©POCΓΘ
ΡψΟ«Ω¥Έ“Ο«ΩΦ≤λΝΥΚήΕύΒΡ…Χ“Β»μΦΰΘ§Έ“Ο«”ΟΝΥ¥σΝΩΒΡΨΪΝΠά¥ΩΦ≤λ’β–©…Χ“Β»μΦΰΤΫΧ®ΓΘ
»ΜΚσΉήΒΡά¥Ω¥Θ§Έ“ΒΟ≥ω’β―υΒΡΫα¬έΘ§ΒΎ“ΜΗωΨΆ «»μΦΰΙΐ”Ύ≈”¥σΘ§ΨΆ «’βάοΟφΚήΕύΒΡΙΠΡήΘ§”–Έ“œκ“ΣΒΡΙΠΡήΘ§ΒΪ «”–ΚήΕύ“≤ «≤Μœκ“ΣΒΡΘ§ΒΪ «’βΗωΕΪΈς“ρΈΣ «“ΜΗω≥… λΒΡ…Χ“Β»μΦΰΘ§Υυ“‘≤ΜΙή‘θΟ¥―υΡψΕΦΒΟ“ΣΓΘ
’βΗω±®Φέ‘ΛΥψ’βΗωΨΆ≤ΜΨΏΧεΥΒΝΥΘ§“ρΈΣΈ“Ο«ΡΩΒΡ“≤ «≤ΜΫωΫωœκ ‘“Μ ‘Θ§Εχ «œκ―Γ‘ώ“ΜΗω≤ζΤΖœΏΘ§Έ“Ο«Έ¥ά¥ΝΫΒΊ»ΐ÷––Ρ’ϊΗω…ζ≤ζœΒΆ≥Θ§Έ“ΕΦœκ“ΣΆ®Ιΐ’β“ΜΗω≤ζΤΖœΏΙήάμΤπά¥Θ§Υυ“‘ΥΒ“ρΈΣΈ“Ο«’βΗω‘ΛΤΎ±»Ϋœ¥σΘ§ΥϊΟ«ΒΡΈΗΩΎ“≤±»Ϋœ¥σΘ§Υυ“‘±®Φέ «≥§≥ωΈ“Ο«ΒΡ‘ΛΥψΒΡΓΘ
POC –ßΙϊ «Οψ«ΩΒΡΘ§’βΗωΚήΡ―Α―ΗωΗωΕΦ≤βΒΫΒψΘ§Εχ«“ΚήΕύΒΡΙΠΡήœκΉω≤Δ≤Μ «œκΉωΨΆΩ…“‘ΉωΘ§±»»γΥΒΈ“Β± ±”–“ΜΗωΚήΦρΒΞΒΡΙΠΡή–η«σΘ§‘ΤΤΫΧ® «Οφœρ”ΟΜßΒΡ…ξ«κΘ§ΕχΈ“Ο«’βάοΒΡΙήάμ‘±ΜΙ”–“ΜΗω–η«σΘ§ΨΆ «Έ“Α―–ιΡβΜζ≈δ÷Ο«εΒΞ–Έ≥… Excel ΈΡΦΰΒΦ»κΫχœΒΆ≥Θ§œΒΆ≥ΨΆΉ‘Ε·ΑοΈ“Α―–ιΡβΜζ»Ϊ≤ΩΫ®ΚΟΓΘ
ΒΪ «Β± ±Έ“Ο«Ηζ≥ß…ΧΫ”¥ΞΒΡΖ¥άΓΨΆ «ΥΒΘ§’βΗωΙΠΡή–η“ΣΝμΆβΩΣΖΔ“ρΈΣΥϊΟ«ΒΡ≤ζΤΖ «ΟΜ”–’βΗωΙΠΡήΘ§–η“ΣΝμΆβ‘ΌΩΣΖΔΘ§άύΥΤ’β÷÷Ε®÷ΤΜ·ΩΣΖΔΜΙ”–ΚήΕύΘ§Υυ“‘’βΗωΩΣΖΔΝΩ «Κή¥σΒΡΓΘ
≤Ο¥“βΥΦΡΊΘΩ±»»γΈ“Ο«œ÷‘Ύ»Υ ΌΒΡ”–“ΜΗω‘Τ÷ζάμΤΫΧ®”–“ΜΗωœϊœΔΆΤΥΆΙΠΡήΚΆΈ“Ο«œκ“Σ“ΐΫχΒΡ…Χ“ΒΤΫΧ®’ϊΚœΤπά¥Θ§Μρ’Ώ «ΕΧ–≈’ϊΚœΤπά¥ΉωΆΤΥΆΘ§Ήή÷°’β–©ΕΦ «Ζ«≥ΘάßΡ―ΒΡΕΦ «–η“ΣΩΣΖΔΒΡΘ§ΟΩ“ΜΗωΒψ…œΕΦ«°ΕΦ «–η«σΕΦ «ΆΕ»κΘ§“ρΈΣ’β–©÷÷÷÷‘≠“ρ ΒΦ …œΈ“Ο«’βΗω≤…ΙΚΤΫΧ®ΒΡ–η«σ «≥Ό≥ΌΒΟ≤ΜΒΫΝλΒΦΒΡ≈ζΉΦΓΘΥυ“‘’β «ΚήΆ¥ΩύΒΡ“ΜΗω ¬«ιΓΘ
Κσά¥Έ“Ο«ΉνΚσΨωΕ®ΉωΉ‘÷ςΩΣΖΔΘ§“ρΈΣΒ± ±’ΐΚΟ «14ΡξΨ≈‘¬ΖίΒΡ ±ΚρΘ§“χΦύΜα≥ωΝΥ“ΜΗωΈΡΘ§ΨΆ «“Σ«σ Βœ÷Έ“Ο«ΙζΡΎΫπ»Ύ––“ΒΒΡ“ΜΗω–≈œΔœΒΆ≥Α≤»ΪΩ…ΩΊΒΡΈΡΦΰΘ§’βΗωΈΡΦΰœ¬ά¥“‘ΚσΘ§ΝλΒΦΧ§Ε»ΨΆ±δΝΥΘ§ΝλΒΦΨΆ «ΥΒΙΡάχΡψΟ«ΉωΉ‘÷ς―–ΖΔΘ§Έ“Ο«Ά§ ±“≤¥φ‘ΎΙφΡΘΤΩΨ±Θ§¥σΦ“Ω…“‘Ω¥’β «ΦΗΗωΆΦΓΘ
<img src="http://www.greatops.net/zb_users/upload/2017/04/20170417203534149243253414572.jpeg" data-w="1280" original="http://www.greatops.net/zb_users/upload/2017/04/="img-responsive" style="box-sizing: border-box; border: 0px; vertical-align: middle; display: inline-block; max-width: 100%; height: auto;"/>
’βΗω «Έ“Ο«“‘«Α‘Ύ…œΚΘΦ·ΒγΗέΒΡ“ΜΗωΜζΖΩΘ§ΥφΉ≈ΙφΡΘ…œΟφ“‘ΚσΘ§≥…±Ψ «‘Ϋά¥‘ΫΗΏΒΡΓΘΕχ«“Έ“Ο«‘Ύ’β±ΏΈ“Ο«”–ΚήΕύ“≤ΜΙ «”–¥σΝΩΒΡΦΦ θΒΡ≥ΝΒμΘ§Έ“Ο«œ÷‘ΎΨΆ « OCM ”–ΤΏΗωΘ§CCIE “≤”–ΈεΝυΗωΘ§ «ΡήΙΜΗ…“ΜΒψ ¬ΒΡΓΘ
Τδ ΒΉςΈΣ“ΜΗωΟΜ”–’β÷÷Ψ≠―ιΒΡ“ΜΗω¥ΪΆ≥ΙΪΥΨΘ§“Σά¥Ήω’β–© ¬«ι «ΚήΡ―ΒΡΘ§“ρΈΣΡψΧΊ±π «ΉΏ≥ωΒΎ“Μ≤ΫΘ§Ζ«≥ΘΡ―ΓΘ“ρΈΣ÷°«ΑΈ“Ο«ΕΦΨθΒΟ“ΣΉω’β–©ΕΪΈςΘ§“ΣΉ‘ΦΚά¥ΉωΦρ÷± «≤ΜΩ…ΥΦ“ιΒΡΘ§Κσά¥Έ“Ο«“≤ «ΉωΝΥ¥σΝΩΒΡPOC―ι÷ΛΘ§»Ξ―Γ‘ώ“ΜΗωΩΣ‘¥ΒΡΩρΦήΉω’βΗω ¬«ιΓΘ
ΗυΨίΈ“Ο«œ÷”–ΒΡ«ιΩωΘ§ ΒΦ …œΈ“Ο«”–“Μ≤ΩΖ÷ «ΩΣ‘¥ΒΡΕΪΈςΘ§’βΗω «Έ“Ο«―–ΖΔΤΫΧ®Θ§Έ“Ο«”Ο’βΗω openstack ά¥ΉωΓΘΜΙΚΟΨΆ « vmware ΒΡ vsphere API «»ΪΩΣΖ≈ΒΡΘ§ΥϊΟΩ“ΜΗωΑφ±ΨΒΡSDKΕΦ «Ω…“‘œ¬‘ΊΒΡΘ§Ω…“‘ΗχΡψΉω÷ΗΒΦΘ§Έ“Ο«Μυ”Ύ’βΗωΉωΕ®÷ΤΜ·ΒΡΙΛΉςΘ§Έ“Ο«”Π”ΟΦύΩΊ «ΉωΝΥ¥σΝΩΒΡ»’÷ΨΆΎΨρΓΘ
»ΜΚσΜυ¥ΓΤΫΧ®ΦύΩΊΈ“Ο« «Μυ”ΎΩΣ‘¥ΉωΆξ»ΪΒΡ÷Ί–¬ΤσΜ°Θ§Έ“Ο«’βΗω «“―Ψ≠¥οΒΫΟΩΧλ“ΜΗω“ΎΒΡΦύΩΊ–≈œΔ≤…Φ·ΙφΡΘΓΘ¥σΗ≈ «”– °Ηω zabbix proxyΘ§ΨΆΩ…“‘ΩΗΉΓΝΥΓΘ

Έ“Ο«ΒΡ÷ςΫγΟφΈ“Ο«”ΟΝΥ±»Ϋœ”–“βΥΦΒΡΩρΦήΨΆ « primefacesΘ§ΩλΥΌΒΡ“ΜΗω WEB ΉιΦΰΩΣΖΔΒΡ“ΜΗωΩρΦήΈ“Ο«“ΤΕ·ΕΥ «”ΟΒΡ JQueryΓΘΈ“Ο«‘ΎΝς≥ΧΖΫΟφΈ“Ο«ΜΙ «”ΟΝΥ“ΜΗωΩΣ‘¥ΒΡΤΫΧ®ΨΆ « ActivitiΘ§Ή‘Ε·Μ·Έ“Ο«÷ς“Σ «”Ο zabbix ΒΡAPIά¥ Βœ÷ΟϋΝνΆ≥“ΜΆΤΥΆΚΆ≈δ÷Ο≤…Φ·ΓΘ
ΒΦ …œΉ‘Ε·Μ·Έ“Ο«”ΟΝΥΝΫΩιΘ§“ΜΗω «Ά®Ιΐ rundeck Ήω≈ζΉς“ΒΘ§ΜΙ”–“Μ–©Μυ”ΎsshΒΡ“ΜΗωΆΤΥΆΘ§Έ“Ο«ΜΙ”Ο“ΜΗω zabbix ¥χ”–“ΜΗωΗφΨ·Ή‘Ε·–όΗ¥ΙΠΡή”–“ΜΗωAPIΘ§Έ“Ο«άϊ”Ο’βΗωΉωΝΥ“ΜΗωΫ≈±ΨΆΤΥΆΙΠΡήΓΘ
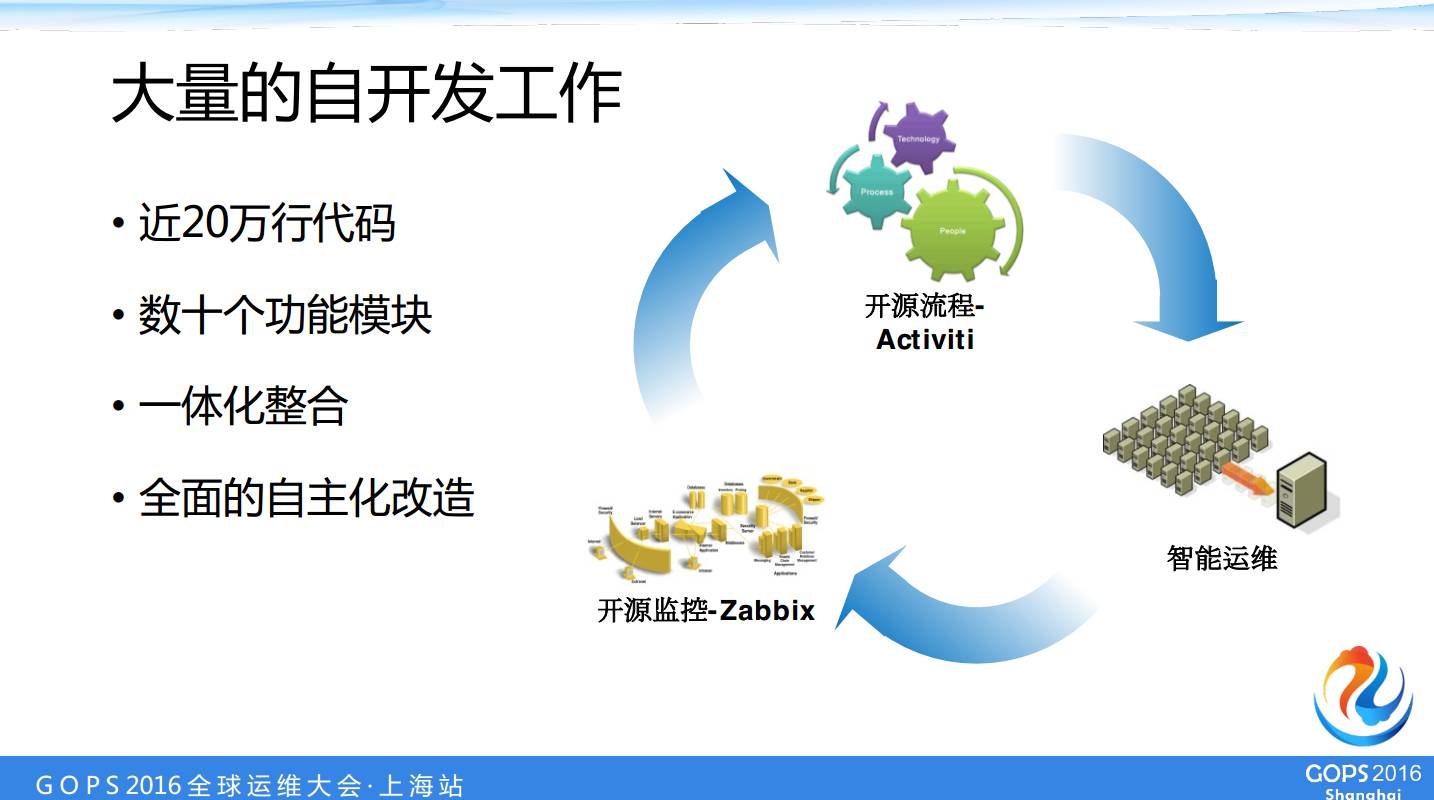
Έ“Ο« «Ή‘÷ς―–ΖΔ’ϊΚœ≤ΜΆ§ΩΣ‘¥ΚΆ≤ΜΩΣ‘¥ΙΛΨΏΘ§»ΎΚœœ÷”–ΒΡ…ζΧ§ΜΖΨ≥Θ§ΨΓΝΩΫΎ ΓΩΣΖΔ»ΥΝΠΘ§œ÷‘Ύ¥σΗ≈ «20Άρ––¥ζ¬κΘ§’βΗω–¥ΝΥ“ΜΡξΕύ–¥≥ωά¥Θ§’βΗωΝΩ“≤≤Μ–ΓΘ§”– ΐ °ΗωΙΠΡήΡΘΩιΓΘ
œ÷‘ΎΈ“Ο«Μυ±Ψ…œΡΩ«ΑΈ“Ο« « zabbixΘ§“―Ψ≠ «»ΪΟφΗ≤Η«Βτ…Χ“ΒΦύΩΊ»μΦΰΒΡΥυ”–ΒΡΦύΩΊΒψΓΘActiviti ’β±ΏΈ“Ο«ΒΡΫτΦ±±δΗϋΘ§ΜΙ”–Ή ‘¥ΒΡ…œœΏΕΦά¥ΉΏ ActivitiΘ§Εχ≤Μ «”Ο‘≠ά¥ΒΡ…Χ“ΒΝς≥Χ»μΦΰΝΥΘ§Έ“Ο«ΉΏ÷π≤ΫΒΡΧφΜΜΒΡ’β÷÷ΖΫ ΫΓΘ
ΉιΦΰΈ“Ο«ΨΆ « Ι”ΟΝΥ PrimefacesΘ§Έ“Ο«ΚσΟφΒΡΩρΦή÷ς“Σ «Μυ”Ύ JSF ΚΆ springΓΘΈ“Ο«ΩΣΖΔΒΡΥΌΕ» «ΚήΩλΒΡΘ§ΙΠΡή…œœΏΜυ±Ψ…œ“ΜΗω–¬ΙΠΡή“Μ÷ήΨΆΩ…“‘…œ»ΞΓΘ
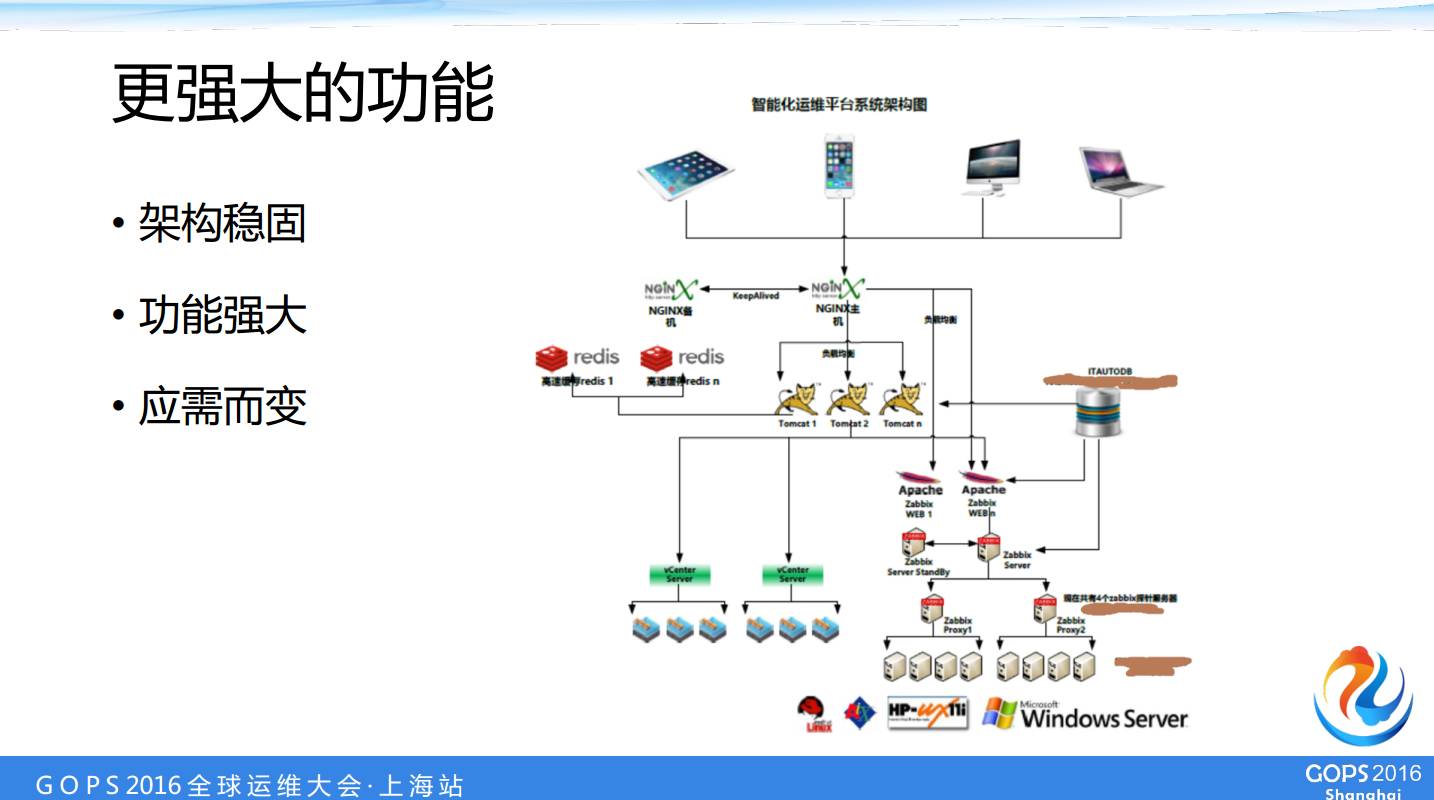
’β «“ΜΗωΦρΒΞΒΡΦήΙΙΘ§Έ“Ο«œ÷‘Ύ’β“ΜΗωΤΫΧ® «Μυ”Ύ JQuery Mobile ΒΡΫγΟφΘ§ΨΆ «Έ“Ο«’βΗωΫγΟφΨΆ «Ή‘ ”ΠΒΡΘ§≤ΜΙή « ≤Ο¥÷’ΕΥΖΟΈ ΕΦΩ…“‘Ή‘Ε·ΒΡ ”ΠΡψΒΡΤΝΡΜΓΘ
Έ“Ο««ΑΕΥ « Nginx ΉωΗΫ‘ΊΨυΚβΘ§ΚσΟφ «”– Redis «ΗΏΥΌΜΚ¥φΒΡΓΘΦΗΗωΉιΒΡ Tomcat «ΉωΈ“Ο«ΒΡ»ΈΈώΒΡΒςΕ»Ϋ≈±ΨΒΡΖ÷ΖΔ“‘ΦΑ–ιΜζΒΡΙήΩΊΘ§‘ΤΤΫΧ®ΒΡΙήΩΊΘ§’βΚσΟφ «Έ“Ο«ΒΡ vsphere API ΚΆ openstack APIΓΘœ¬Οφ”– zabbix proxy ’βάοΜ≠…ΌΝΥΘ§Έ“Ο«œ÷‘Ύ proxy “―Ψ≠”– °ΕύΗωΓΘ

’β «Έ“Ο«ΒΡΉ‘ΦΚ±ύ–¥ΒΡ‘ΤΤΫΧ®ΒΡΫγΟφΘ§Έ“Ο«ΡΎ≤Ω Ι”ΟΉ ‘¥±“ΩΊ÷ΤΉ ‘¥œϊΖ―Θ§Ρψ”Ο“ΜΗω‘¬ΜΙ «”ΟΑκΡξΦέ«° «≤Μ“Μ―υΒΡΘ§»ΜΚσ“ρΈΣΆ®Ιΐ’βΗωΜΖΨ≥ΙήάμΤπά¥Θ§Έ“Ο«―–ΖΔΜΖΨ≥ΥϊΟ«‘Ύ“≤≤ΜΗ“άΥΖ―ΝΥΓΘ
ΕΦ «ΡΎ≤ΩΒΡΩΆΜßΘ§Τδ Β’βΗωΦέΗώ“≤≤ΜΚΟΈ“Ο«ΥψΘ§ΒΪ «Έ“Ο«”–’βΟ¥“ΜΗωΜζ÷Τ“‘ΚσΘ§―–ΖΔ‘Ύ Ι”ΟΉ ‘¥ΒΡ ±ΚρΨΆ≤ΜΜα»”‘ΎΡ«ΙΐΝΥ“ΜΡξΝΫΡξΜΙ‘Ύ≈ήΟΜ»ΥΙήΓΘ

’βΗω «Έ“Ο«Ήω‘ΥΈ§Ζ÷ΖΔΒΡΙΛΨΏΩβΘ§Εχ«“Έ“Ο«ΟΩ“ΜΗωΆΤΥΆΒΡΫ≈±ΨΕΦ «ΉωΝΥœξœΗΒΡ»’÷ΨΘ§Εχ«“Έ“Ο«Ά®Ιΐ’β–©Ϋ≈±ΨΒΡΙ±œΉ’ΏΘ§Ω…“‘»ΞΩΦΚΥΈ“Ο«ΟΩ“ΜΗωœΒΆ≥Ιήάμ‘±‘ΎΈ“Ο«÷Σ ΕΩβάοΟφΒΡΙ±œΉΕ»ΓΘ
œ÷‘ΎΈ“Ο« Βœ÷ΒΡΙΠΡήΘ§≤Μ÷Μ «’β–©Θ§ΉνΗΏ–ßΒΡ «»ΞΡξΈ“Ο«”–“ΜΗωX86ΜζΖΩΕΦ «±»Ϋœ»»Θ§–η“ΣΙΊΜζΘ§’βΗωΈ“Ο«Ής”ΟΖΔΜ”ΝΥΖ«≥Θ¥σΒΡΉς”ΟΘ§Έ“Ο«“ΜΗωΑ¥≈Ξœ¬»Ξ200ΕύΧ®ΜζΤςΨΆΗψΕ®ΝΥΓΘ
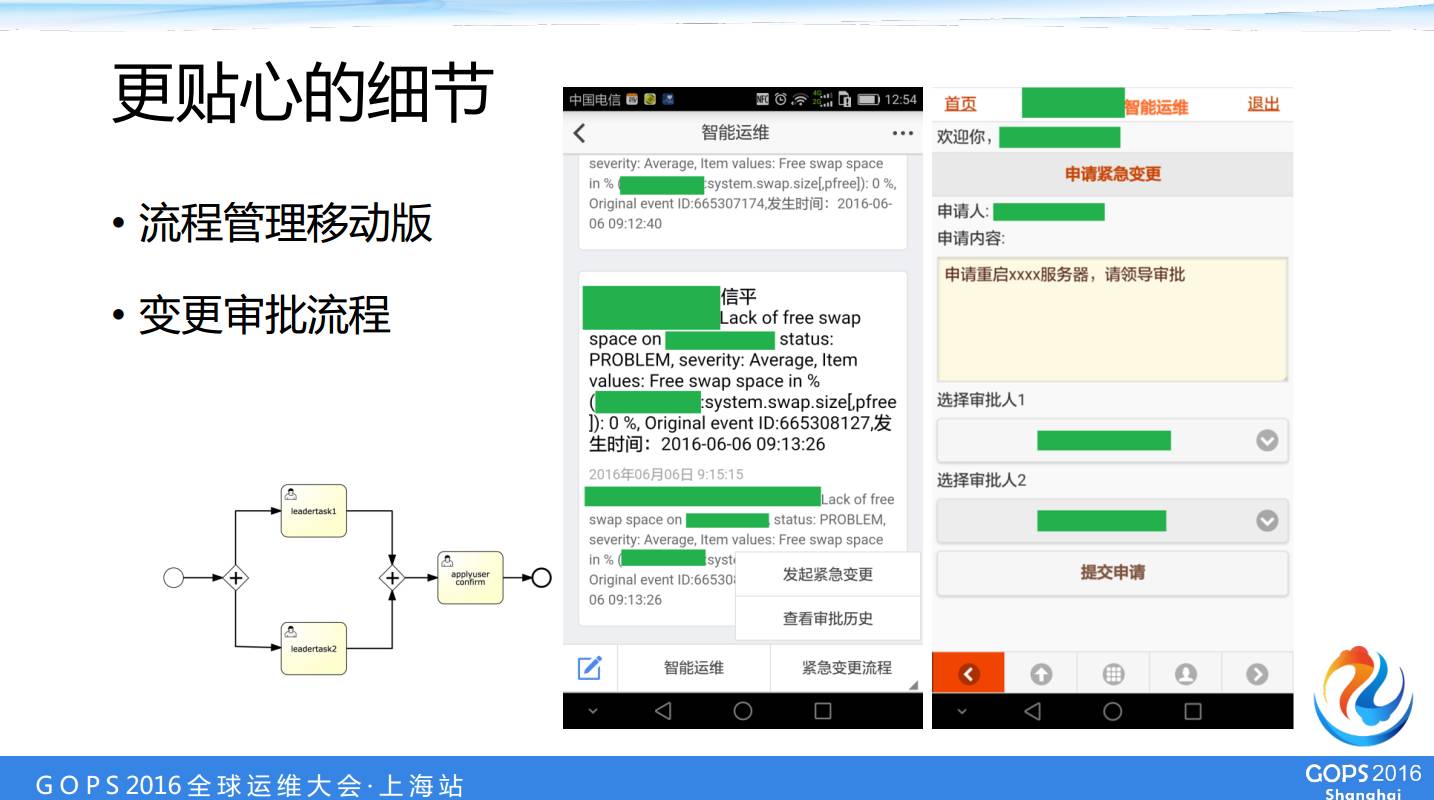
œ÷‘ΎΩ¥ΒΫΒΡ’βΗω «Έ“Ο«“ΤΕ·ΑφΒΡΙΠΡήΘ§’β «Έ“Ο«ΒΡ÷ςΜζ±δΗϋΒΡΝς≥ΧΘ§Ρψ÷Μ–η“ΣΑ―ΡψΒΡΝς≥ΧΆΦ‘Ύ Activiti άοΟφΜ≠≥ωά¥Θ§Κή…ΌΒΡ±ύ≥ΧΨΆΩ…“‘Α―’βΗωΝς≥Χ≈ήΤπά¥Θ§Ζ«≥Θ«αΝΩΦΕΒΡ’βΟ¥“ΜΗωΜζ÷ΤΓΘœ÷‘ΎΈ“Ο«ΒΡΫτΦ±±δΗϋΜυ±Ψ…œΕΦ «Ά®Ιΐ ÷Μζ…ξ«κΒΡΓΘ
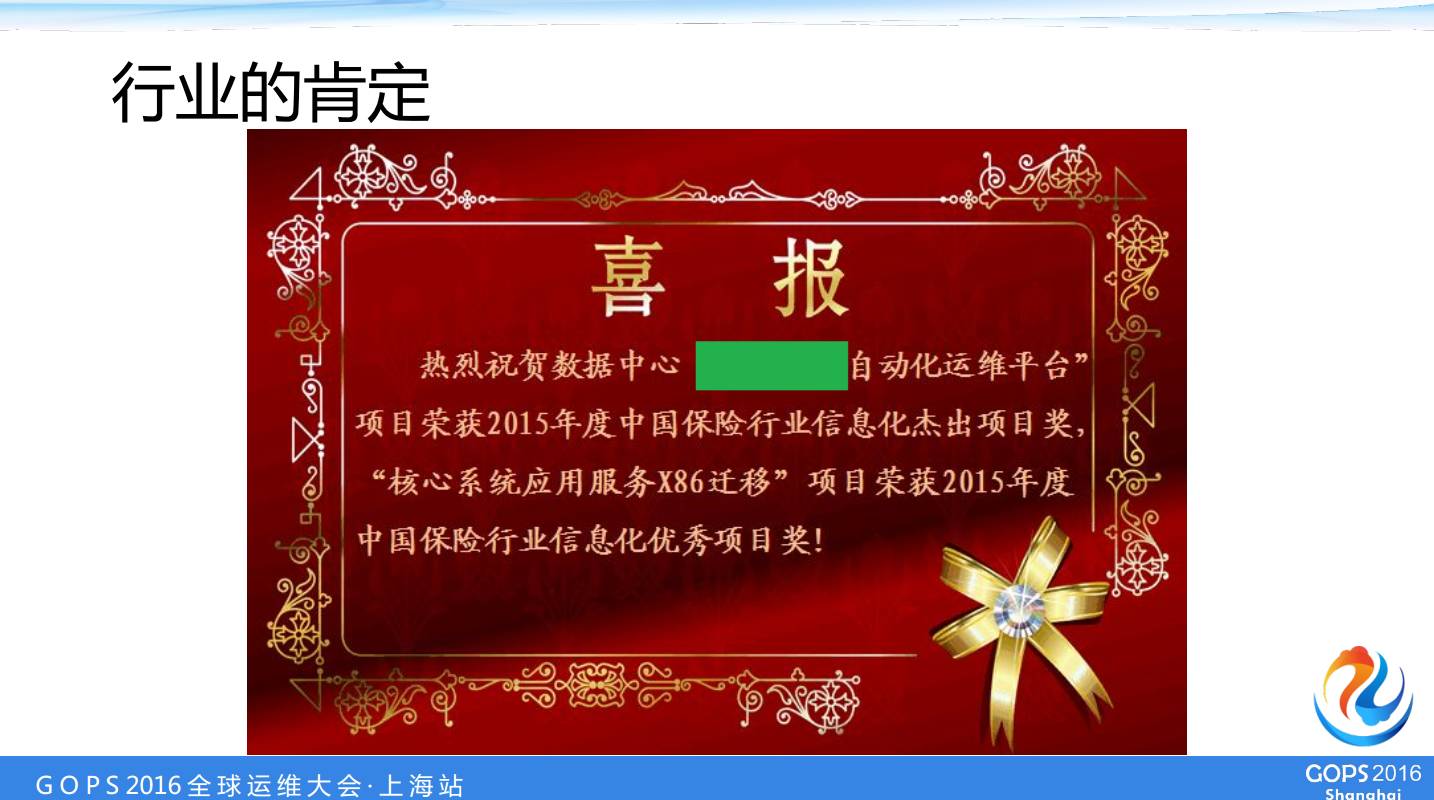
’βΗω «Έ“Ο«œνΡΩ‘Ύ2015»ΞΡξΜώΒΟΝΥ±Θœ’––“Β–≠Μα“ΜΗωΫ±ΓΣΓΣΓΑ2015Ρξ±Θœ’––“Β–≈œΔΜ·Ϋή≥ωœνΡΩΫ±Γ±ΓΘ
3ΓΔΈ¥ά¥ΖΫœρΘΚΉ‘÷ςΩΣΖΔ“ΜΧεΜ·DCOS
œ¬ΟφΫ≤“Μœ¬Έ¥ά¥ΒΡΩΦ¬«Θ§Έ“Ο«ΉωΝΥ“Μ–©–ΓΕΪΈςΘ§Έ¥ά¥Ά®Ιΐ’βΗωΩρΦή≤ΜΕœΒΡΆΊ’Ι»ΞΉ‘÷ς―–ΖΔΦΧ–χ…νΜ·Θ§Ήω≥ω“ΜΗωΉ‘÷ςΩΣΖΔΒΡ“ΜΧεΜ·ΒΡ DCOSΓΘ
Έ“Ο«Ω…“‘Ά®Ιΐ÷¥––Έ“Ο«ΒΡ‘ΥΈ§ΟϋΝνΘ§±»»γΥΒΈ“Ο«‘Ύ“ΤΕ·ΕΥΨΆΩ…“‘Ήω–ιΜζΒΡ“ΜΗωΉ ‘¥«ιΩωΒΡ≤ι―·Θ§“‘ΦΑ–ιΜζΒΡ“Μ–©ΖΰΈώΤςΒΡ÷ΊΤτΘ§ά©’ΙΈ“Ο« ΐΨίΩβΒΡΩ’ΦδΘ§Αϋά®Έ“Ο«Ϋ®ΝΔΜρά©’ΙΈΡΦΰœΒΆ≥Θ§’β–©±ξΉΦΜ·ΒΡ≤ΌΉςΕΦΩ…“‘ΉωΒΡΓΘ
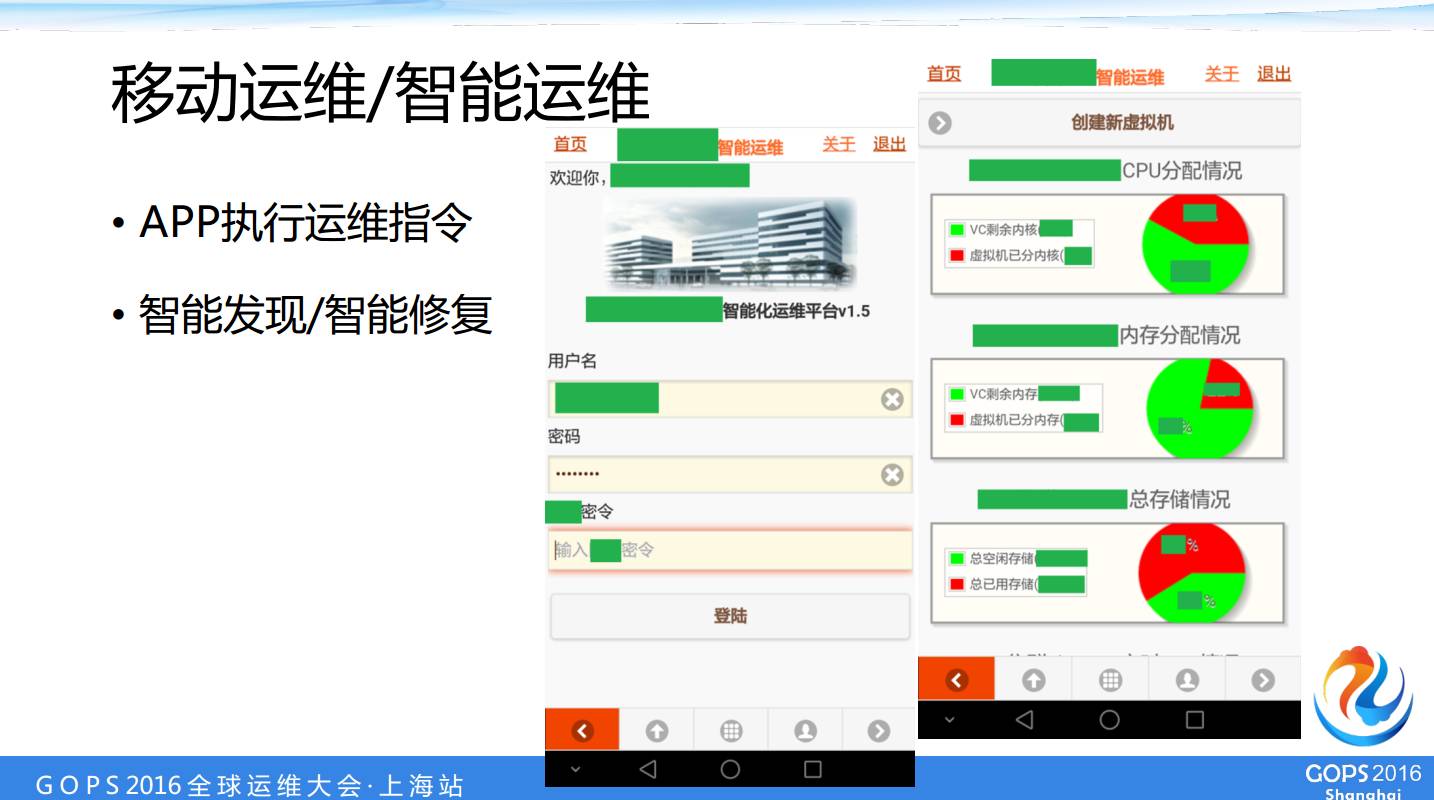
ΝμΆβΈ“Ο«Ω…“‘ΉωΒΫ÷«Ρή–όΗ¥ΓΘ»γΙϊΥΒ“Μ–©ΙήΒΡ≤Μ «ΚήΙφΖΕΒΡΒΊΖΫΘ§ΨθΒΟ’βΗωΚήΦρΒΞΘ§ΖΔœ÷ΝΥ“‘Κσ–όΗ¥ΨΆΩ…“‘ΝΥΘ§ΒΪ «≤Μ––Ρψ±Ί–κ“ΣΝτœ¬±δΗϋΒΡΙλΦΘΘ§Υυ“‘Έ“Ο«“ΣΆ®Ιΐ zabbix Ή‘Ε·ΖΔœ÷ΝΥ“‘ΚσΘ§ΨΆ «Α―’βΗωΉ‘Ε·–όΗ¥ΝΥΘ§»ΜΚσΆ®Ιΐ Activiti Ντœ¬“ΜΗωΫτΦ±±δΗϋΒΡΙλΦΘΘ§‘ΎΈ“Ο«ΒΡΝς≥ΧΙήάμάοΟφΘ§“‘Κσ «”–ΨίΩ…≤ιΒΡΓΘ

»ΜΚσΈ“Ο«ΦΤΜ°ΜΙ «“ΣΟφœρœ÷‘Ύ’β÷÷»ίΤςΦΦ θΉωΈ“Ο«‘Τ PaaS ΤΫΧ®ΒΡΫΜΜΞΘ§ΡΩ«ΑΈ“Ο«–¬“Μ¥ζ PaaS ΤΫΧ® «Ά®ΙΐΒςΈ“Ο«Ή‘Ε·Μ·‘ΥΈ§ΒΡ API ά¥’“Έ“Ο«Υς»Γ–ιΡβΜζΜΖΨ≥Θ§ΡΩ«Α «’β―υΒΡΫ”ΩΎΘ§Έ¥ά¥Έ“Ο«œκΆ®ΙΐΉ‘Ε·Μ·‘ΥΈ§ΤΫΧ®ά¥ΙήάμΈ“ΒΡΨΒœώΚΆ PaaS ΜΖΨ≥ΓΘ
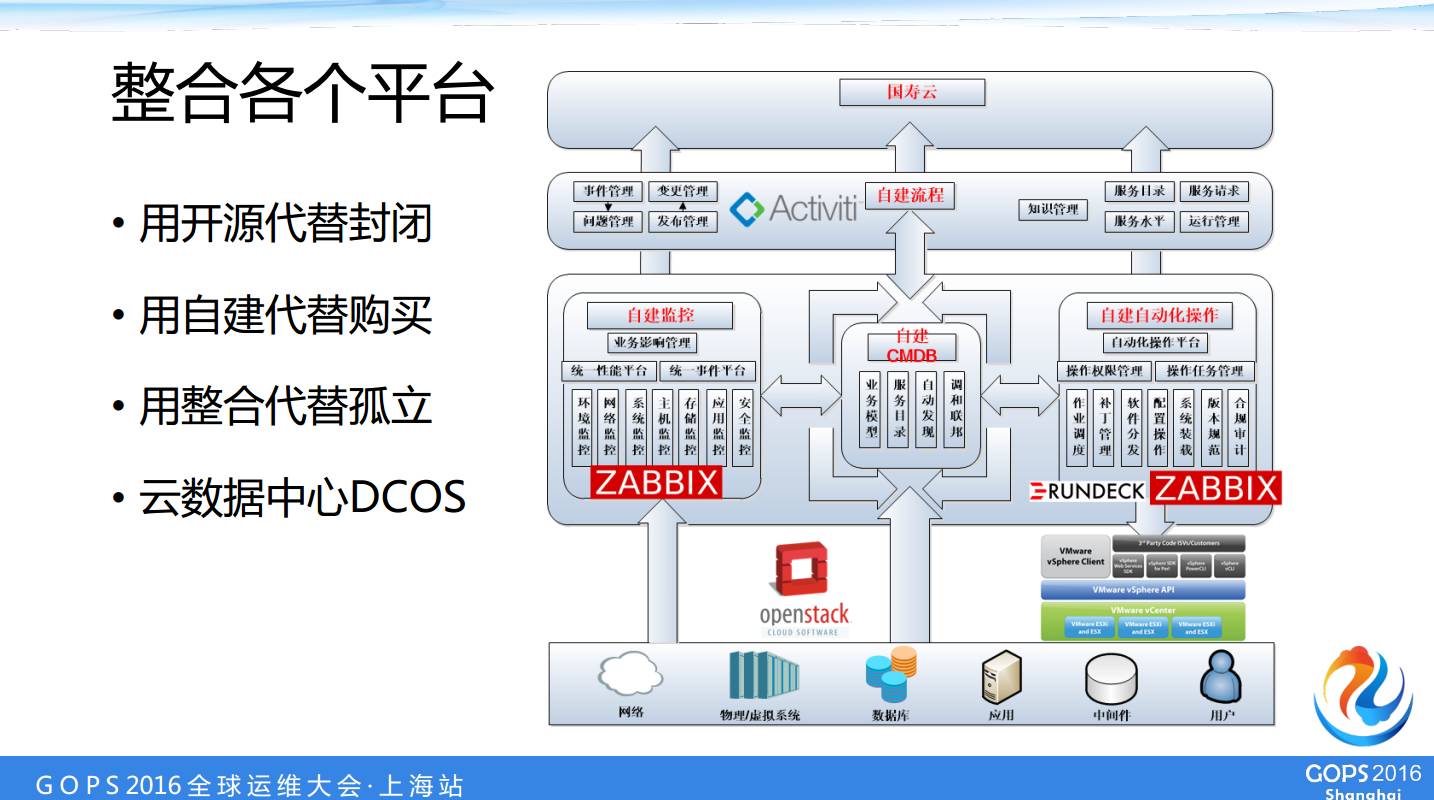
’β «Έ“Ο«ΒΡ“ΜΗω…ηœκΘ§”ΟΩΣ‘¥¥ζΧφΖβ±’Θ§”ΟΉ‘Ϋ®¥ζΧφΙΚ¬ρΘ§”Ο’ϊΚœ¥ζΧφΙ¬ΝΔΓΘΈ“Ο«≥ΔΒΫΝΥ“Μ–©ΧπΆΖΒΪ ««ΑΟφΜΙ”–ΚήΕύΩ”–η“ΣΈ“Ο«ΧΛΓΘ“ρΈΣΈ“Ο« zabbix Ω…“‘Ή‘Ε·ΒΡΑ―’β–©≈δ÷Ο–≈œΔΆΤΙΐ»ΞΘ§Υυ“‘Έ“Ο«œ÷‘Ύ CMDB «ΚήΉΦΒΡΓΘ
»ΜΚσΈ“Ο«‘ΎΗ’≤≈ΒΡ“ΤΕ·ΑφάοΟφΘ§Έ“Ο«”÷Α― CMDB ΒΡ≤ι―·ΉωΫχ»ΞΝΥΘ§“ρΈΣΈ“Ο«œΘΆϊΥυ”–ΒΡΝλΒΦΑϋά®œΒΆ≥Ιήάμ‘±ΕΦΩ…“‘‘Ύ ÷Μζ…œΟφΆ®Ιΐ CMDB ≤ιΒΫ’βΗω…η±ΗΒΡ–≈œΔΓΘ±»»γΈΜ÷Ο–≈œΔ‘ΎΡΡΗωΜζΖΩΡΡΗωΜζΙώΘ§»Ϊ≤ΩΕΦΩ…“‘≤ιΒΫΓΘ
Υυ“‘Έ“Ο« CMDB ΒΦ …œ“ΜΗω «‘¥ΆΖ «ΜνΥ°ΓΘ“ρΈΣ¥”Ή‘Ε·Μ·ΖΔœ÷άοΟφ≥ωά¥ΒΡΘ§œϊΖ― «ΤΒΖ±ΒΡΘ§“ρΈΣΟΩ“Μ¥Έ’“ΖΰΈώΤςΕΦ «Μα”ΟΒΫΥϊΓΘΈ“Ο«“‘«ΑΒΡΖβ±’ΒΡ CMDB “―Ψ≠Άξ»Ϊ≤Μ”ΟΝΥΘ§œ¬ΟφΈ“Ο«Ά®Ιΐ CMDB Α―Έ“Ο«œ÷‘Ύ”–ΒΡΙΛΉςΝς»Ϊ≤ΩΫαΚœΤπά¥ΓΘ
Έ¥ά¥ « ≤Ο¥―υΒΡ«ιΩωΘ§ΝλΒΦ…σ≈ζ“‘ΚσΘ§œΒΆ≥Ιήάμ‘±÷Μ–η“ΣΒψ“Μœ¬ σ±ξ Activiti ΨΆΜαΒςΈ“Ο«ΒΡΉ‘Ε·Νς±ξΉΦΦΰΆξ≥…Κσ–χΒΡΙΛΉςΘ§ΙΛΉςΝςΚΆΉ‘Ε·Μ·ΆξΟά»ΎΚœΘ§Ε‘ΆβΧαΙ©‘ΤΖΰΈώ≤ΥΒΞΘ§’βΗωΨΆ «Έ“Ο«Έ¥ά¥ΒΡΙζ Ό‘ΤΤΫΧ®ΓΘ